
Resumen ejecutivo
Hemos identificado vulnerabilidades en tres bibliotecas Python de inteligencia artificial/aprendizaje automático (IA/ML) de código abierto publicadas por Apple, Salesforce y NVIDIA en sus repositorios GitHub. Las versiones vulnerables de estas bibliotecas permiten la ejecución remota de código (RCE) cuando se carga un archivo de modelo con metadatos maliciosos.
En concreto, estas bibliotecas son:
- NeMo: un marco basado en PyTorch creado con fines de investigación y diseñado para el desarrollo de diversos modelos de IA/ML y sistemas complejos creados por NVIDIA.
- Uni2TS: una biblioteca PyTorch creada con fines de investigación que utiliza Morai de Salesforce, un modelo básico para el análisis de series temporales que pronostica tendencias a partir de vastos conjuntos de datos.
- FlexTok: un marco basado en Python creado con fines de investigación que permite a los modelos de IA/ML procesar imágenes mediante el manejo de las funciones de codificación y decodificación, creado por investigadores de Apple y del Laboratorio de Inteligencia Visual y Aprendizaje del Instituto Federal Suizo de Tecnología.
Estas bibliotecas se utilizan en modelos populares en HuggingFace con decenas de millones de descargas en total.
Las vulnerabilidades provienen de bibliotecas que utilizan metadatos para configurar modelos y canalizaciones complejos, en los que una biblioteca compartida de terceros instancia clases con estos metadatos. Las versiones vulnerables de estas bibliotecas simplemente ejecutan los datos proporcionados como código. Esto permite a un atacante incrustar código arbitrario en los metadatos del modelo, que se ejecutaría automáticamente cuando las bibliotecas vulnerables cargaran estos modelos modificados.
Hasta diciembre de 2025, no hemos encontrado ejemplos maliciosos que utilicen estas vulnerabilidades en la red. Palo Alto Networks notificó a todos los proveedores afectados en abril de 2025 para garantizar que tuvieran la oportunidad de implementar mitigaciones o resolver los problemas antes de la publicación.
- NVIDIA emitió CVE-2025-23304, calificado como de alta gravedad, y lanzó una corrección en la versión 2.3.2 de NeMo.
- Los investigadores que crearon FlexTok actualizaron su código en junio de 2025 para resolver los problemas.
- Salesforce emitió CVE-2026-22584, clasificado como de gravedad alta, e implementó una corrección el 31 de julio de 2025.
Estas vulnerabilidades fueron descubiertas por Prisma AIRS, que es capaz de identificar los modelos que aprovechan estas vulnerabilidades y extraer sus cargas útiles.
Además, los clientes de Palo Alto Networks están mejor protegidos frente a las amenazas mencionadas gracias a los siguientes productos y servicios:
- Gestión de vulnerabilidades de Cortex Cloud
- La evaluación de seguridad de IA de Unit 42 puede ayudar a las organizaciones a reducir el riesgo de adopción de la IA, proteger la innovación en IA y reforzar la gobernanza de la IA.
- Si cree que puede haber resultado vulnerado o tiene un problema urgente, póngase en contacto con el equipo de respuesta ante incidentes de Unit 42.
| Temas relacionados con Unit 42 | Python, LLMs, Machine Learning |
Formatos de modelos de IA/ML
Los procesos de entrenamiento e inferencia de IA/ML dependen del almacenamiento de estados internos complejos, como los pesos aprendidos y las definiciones de arquitectura. Estos estados internos se guardan como artefactos de modelo y los artefactos deben compartirse entre productores y consumidores. Las bibliotecas proporcionan mecanismos integrados para serializar estos artefactos.
Las bibliotecas de Python para IA/ML han dependido durante mucho tiempo de la funcionalidad del módulo pickle de la biblioteca estándar de Python para almacenar y cargar objetos Python en y desde archivos. Este módulo serializa los objetos Python creando un programa sencillo para reconstruir los objetos y el módulo pickle se ejecuta cuando se cargan los objetos Python. Dado que el módulo pickle ejecuta código al cargar archivos, su uso conlleva importantes riesgos de seguridad.
El formato de archivo de la biblioteca PyTorch simplemente incrusta archivos .pickle en un formato contenedor. Otras bibliotecas como scikit-learn utilizan .pickle u otras extensiones utilizadas para pickle (como .joblib) por su cuenta. Las bibliotecas de IA/ML más populares documentan claramente estos riesgos y proporcionan mitigaciones maduras para evitar la ejecución de código inesperado de forma predeterminada.
Problemas de seguridad en los nuevos formatos de modelos
Se han desarrollado nuevos formatos para abordar los problemas de seguridad de estos formatos basados en pickle. Estos formatos "seguros" lo consiguen en gran medida al admitir únicamente la serialización de los pesos de los modelos o al representar los canales como datos en lugar de código, mediante el uso de formatos como JSON. Por ejemplo, el formato safetensors de HuggingFace solo permite el almacenamiento de los pesos de los modelos y un único objeto JSON para almacenar los metadatos de los modelos.
Los formatos más antiguos también han dejado de depender del módulo pickle. Por ejemplo, PyTorch solo carga los pesos del modelo de forma predeterminada. Si se habilita la carga de pickle, PyTorch solo ejecutará funciones de una lista de permitidos predefinida que debería impedir la ejecución de código arbitrario.
Aunque estos nuevos formatos y actualizaciones eliminan la posibilidad de serializar los procesos como código, no hacen que las aplicaciones y bibliotecas que utilizan estos modelos sean inmunes a los exploits tradicionales. Los investigadores de seguridad de JFrog han identificado vulnerabilidades en aplicaciones que utilizan estos formatos mediante técnicas conocidas como XSS y path traversal.
Análisis técnico
Aunque los formatos más recientes han eliminado la posibilidad de almacenar el estado y las configuraciones de los modelos como código, los investigadores siguen teniendo casos de uso para serializar esa información. Dado que estas bibliotecas son grandes y las configuraciones de sus clases pueden ser complejas, muchas bibliotecas utilizan herramientas de terceros para llevar a cabo esta tarea.
Hydra es una biblioteca de Python mantenida por Meta que es una herramienta comúnmente utilizada para serializar el estado del modelo y la información de configuración.
Hemos identificado tres bibliotecas Python de IA/ML de código abierto utilizadas por modelos en HuggingFace que aprovechan Hydra para cargar estas configuraciones desde los metadatos del modelo de una manera que permite la ejecución de código arbitrario:
- NeMo: un marco basado en PyTorch creado con fines de investigación y diseñado para el desarrollo de diversos modelos de IA/ML y sistemas complejos creados por NVIDIA.
- Uni2TS: una biblioteca PyTorch creada con fines de investigación que utiliza Morai de Salesforce, un modelo básico para el análisis de series temporales que pronostica tendencias a partir de vastos conjuntos de datos.
- FlexTok: un marco basado en Python creado con fines de investigación que permite a los modelos de IA/ML procesar imágenes mediante el manejo de las funciones de codificación y decodificación, creado por investigadores de Apple y del Laboratorio de Inteligencia Visual y Aprendizaje del Instituto Federal Suizo de Tecnología.
Hydra
Todas las vulnerabilidades que identificamos utilizan la función hydra.utils.instantiate(), cuya finalidad es "instanciar diferentes implementaciones de una interfaz".
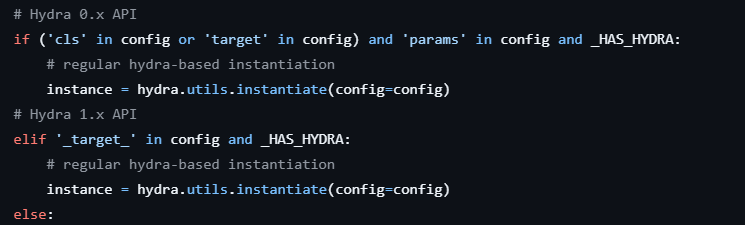
La API de Hydra toma como argumentos un objeto de configuración (como un diccionario Python o un objeto OmegaConf) que describe la interfaz de destino que se va a instanciar y los parámetros opcionales *args y **kwargs que se van a pasar a esa interfaz. Esta configuración espera un valor _target_ que especifique la clase o la función invocable que se va a instanciar, y un valor _args_ opcional que defina los argumentos para _target_.
En cada uno de los casos que identificamos, hydra.utils.instantiate() solo se utiliza para instanciar instancias de clases de biblioteca con argumentos simples almacenados en metadatos. En la Figura 1 se muestra un ejemplo de los metadatos que NeMo pasa a la función instantiate().
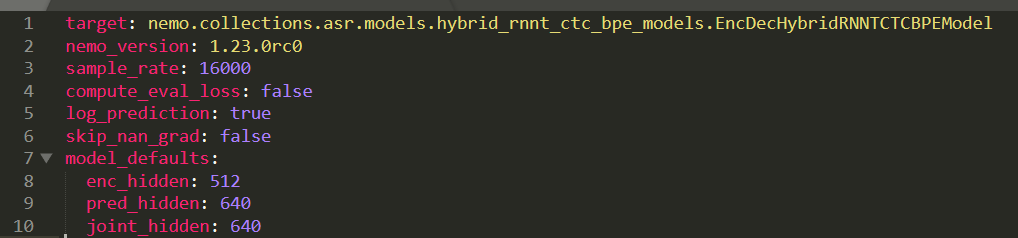
Lo que estas bibliotecas parecen haber pasado por alto es que instantiate() no solo acepta el nombre de las clases que se van a instanciar. También toma el nombre de cualquier función invocable y le pasa los argumentos proporcionados.
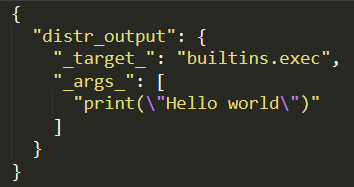
Aprovechando esto, un atacante puede lograr más fácilmente un RCE utilizando funciones integradas de Python como eval() y os.system(). En todas las pruebas de concepto que utilizamos para probar estas vulnerabilidades, empleamos una carga útil utilizando builtins.exec() como la función invocable y una cadena que contenía Python como argumento.
Desde que se identificaron estos problemas por primera vez, Hydra se ha actualizado para agregar una advertencia a su documentación indicativa de que es posible realizar RCE al utilizar instantiate() y para agregar un sencillo mecanismo de lista de bloqueo. Este mecanismo funciona comparando el valor _target_ con una lista de funciones peligrosas como builtins.exec() antes de que se invoque.
Dado que este mecanismo utiliza coincidencias exactas con los objetivos de importación antes de que se importen, se puede eludir fácilmente mediante el uso de importaciones implícitas de la biblioteca estándar de Python (por ejemplo, enum.bltns.eval) o de la aplicación de destino (por ejemplo, nemo.core.classes.common.os.system). Sin embargo, la documentación de Hydra indica claramente que este mecanismo no es exhaustivo y no se debe confiar únicamente en él para impedir la ejecución de código malicioso. A fecha de enero de 2026, este mecanismo de lista de bloqueo aún no está disponible en ninguna versión de Hydra.
NeMo
NVIDIA lleva desarrollando la biblioteca NeMo desde 2019, como un "marco de IA generativa escalable y nativo de la nube". NeMo utiliza sus propios formatos de archivo con las extensiones .nemo y .qnemo, que son simplemente archivos TAR que contienen un archivo model_config.yaml que almacena los metadatos del modelo junto con un archivo .pt o un archivo .safetensors, respectivamente.
Los principales puntos de entrada para cargar estos archivos de modelo .nemo son restore_from() y from_pretrained() Hay varias capas de abstracción, pero en última instancia, la mezcla de serialización se utiliza para gestionar la carga de la configuración del modelo una vez que se ha cargado desde el archivo model_config.yaml incrustado. En la Figura 2 se muestra la llamada vulnerable a hydra.utils.instantiate().
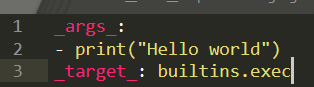
En ningún momento se realiza ninguna desinfección de los metadatos antes de pasarlos a instantiate(). Dado que la llamada se realiza antes de que la clase del modelo de destino comience su inicialización, es fácil crear un archivo model_config.yaml con una carga útil que funcione, como se muestra en la Figura 3.
NeMo también se integra con HuggingFace y admite pasar el nombre de un modelo alojado en HuggingFace a from_pretrained(), que es la forma en que parecen utilizarse la mayoría de los modelos de NeMo en HuggingFace. Esta llamada también es vulnerable porque una vez que se descarga el modelo de HuggingFace, se siguen las mismas rutas de código.
En enero de 2026, más de 700 modelos de HuggingFace de diversos desarrolladores se proporcionan en formato NeMo. Muchos de estos modelos se encuentran entre los más populares de HuggingFace, como el parakeet de NVIDIA. Esta vulnerabilidad parece existir al menos desde 2020.
El formato PyTorch que amplía NeMo admite la ejecución de código con archivos .pickle incrustados, pero lo documenta claramente. Este formato PyTorch también deshabilita la ejecución arbitraria de forma predeterminada y ofrece varias medidas de seguridad, como la lista de módulos permitidos durante la carga de archivos .pickle. NeMo permite la carga de archivos .pickle incrustados dentro de los archivos PyTorch incrustados en archivos .nemo, pero el mecanismo de lista de permitidos integrado en PyTorch debería impedir la ejecución de código arbitrario.
NVIDIA reconoció este problema, publicó un registro CVE CVE-2025-23304 calificado como de gravedad alta y publicó una corrección en la versión 2.3.2 de NeMo.
Para abordar este problema, NeMo agregó una función safe_instantiate para validar los valores _target_ de las configuraciones de Hydra antes de que se ejecuten. Esta función busca de forma recursiva los valores _target_ en la configuración y valida cada uno de ellos, lo que impide el uso de objetos anidados para RCE. Una nueva función _is_target_allowed comprueba primero cada valor _target_ con una lista de prefijos permitidos que contiene nombres de paquetes de NeMo, PyTorch y bibliotecas relacionadas.
Esta comprobación de prefijos por sí sola no sería suficiente para evitar las importaciones implícitas de módulos peligrosos, como es el caso del nuevo mecanismo de lista de bloqueo de Hydra. Sin embargo, NeMo importa adicionalmente cada objetivo utilizando Hydra y comprueba si:
- Es una subclase de una clase esperada.
- La importación tiene un nombre de módulo de una lista de permitidos de módulos esperados.
Al comprobar el valor real importado con estas listas de permitidos, NeMo garantiza que solo se ejecuten los objetivos esperados. Por ejemplo, el objetivo nemo.core.classes.common.os.system se resuelve en el módulo posix, que claramente no forma parte de la biblioteca NeMo.
Uni2TS
En 2024, el equipo de investigación de IA de Salesforce publicó un artículo titulado Unified Training of Universal Time Series Transformers (Formación unificada de transformadores de series temporales universales), en el que se presentaba un conjunto de modelos publicados en HuggingFace. Esta investigación y el uso de estos modelos dependen de uni2TS, una biblioteca Python de código abierto que acompañaba al artículo de Salesforce.
La biblioteca uni2TS funciona exclusivamente con archivos .safetensors, que fueron diseñados explícitamente para proporcionar una alternativa segura a los formatos de modelos que permiten la ejecución de código. El formato safetensors tampoco admite explícitamente el almacenamiento de configuraciones de modelos o canalizaciones.
Para facilitar el almacenamiento de estas configuraciones, bibliotecas como huggingface_hub de HuggingFace utilizan un archivo config.json almacenado en el repositorio de un modelo. En el caso de los modelos que utilizan clases de una de las bibliotecas principales de ML de HuggingFace, esto se hace de forma segura, ya que solo se utilizan parámetros que se pueden almacenar directamente en tipos primitivos JSON. A continuación, estos valores se pasan a un conjunto predefinido y codificado de clases.
Sin embargo, huggingface_hub proporciona una interfaz PyTorchModelHubMixin para crear clases de modelos personalizadas que se pueden integrar con el resto de su marco. Como parte de esta interfaz, los valores se leen del archivo config.json empaquetado y se pasan a la clase del modelo.
Esta interfaz proporciona un mecanismo poco utilizado para registrar funciones denominadas codificadores, que procesan argumentos específicos antes de que se pasen a la clase. La biblioteca uni2TS aprovecha este mecanismo para decodificar la configuración de un argumento específico mediante una llamada a hydra.utils.instantiate() antes de que se pase a la clase de destino, como se muestra en la Figura 4.
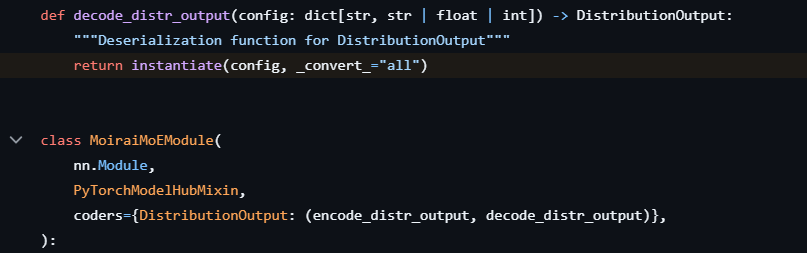
Este código se ejecuta cuando se carga uno de los modelos publicados utilizando MoraiModule.from_pretrained() o MoraiMoEModule.from_pretrained(). Al agregar nuestra carga útil al archivo config.json empaquetado con los modelos mediante uni2TS, como se muestra en la Figura 5, se puede lograr RCE cuando se carga el modelo.
Los modelos de Salesforce que utilizan estas bibliotecas tienen hasta ahora cientos de miles de descargas en Hugging Face. Otros usuarios también han publicado varias adaptaciones de estos modelos en HuggingFace. No se ha descubierto ninguna prueba de actividad maliciosa relacionada con estos modelos.
Salesforce reconoció este problema, publicó un registro CVE CVE-2026-22584, calificado como de gravedad alta, y publicó una corrección el 31 de julio. Esta corrección implementa una lista de permitidos y una estricta comprobación de validación para garantizar que solo se puedan ejecutar los módulos explícitamente permitidos.
ml-flextok
A principios de 2025, Apple y el Laboratorio de Inteligencia Visual y Aprendizaje del Instituto Federal Suizo de Tecnología (EPFL VILAB) publicaron una investigación en la que presentaban una biblioteca Python de apoyo llamada ml-flextok. Al igual que uni2TS, ml-flextok funciona exclusivamente con el formato safetensors y amplía PyTorchModelHubMixin. También puede cargar metadatos desde un archivo config.json incluido en el repositorio del modelo. Esta biblioteca también admite la carga directa de datos de configuración desde el archivo .safetensors, almacenando esta información en la sección de metadatos del archivo bajo la clave __metadata__.
Dado que el formato safetensors representa los metadatos como un diccionario con claves y valores de cadena, y que la configuración del modelo depende de listas de parámetros, es necesario utilizar una codificación secundaria. Ml-flextok aprovecha Python como codificación secundaria y utiliza ast.literal_eval() en la biblioteca estándar de Python para decodificar los metadatos.
Según se ha documentado, esta función no permite la ejecución de código arbitrario, pero es susceptible de sufrir ataques que provocan agotamiento de la memoria, consumo excesivo de CPU y fallos en los procesos. Una vez descodificados los metadatos, ml-flextok los pasa directamente a hydra.utils.instantiate().
Si el modelo se carga desde HuggingFace, estos metadatos se leen desde config.json y no se codifican dos veces, ya que se admiten estructuras complejas. Estos datos JSON se cargan como un diccionario y las secciones específicas se pasan directamente a instantiate().
En ambos casos, las cargas útiles se crean con nombres que coinciden con los argumentos de instantiate(). Dependiendo de si la carga útil se agrega directamente al archivo .safetensors o al archivo config.json empaquetado, la codificación y la ubicación de la carga útil difieren ligeramente, pero la carga útil sigue siendo sencilla. En la Figura 6 se muestra una carga útil colocada en los metadatos de un archivo .safetensors.

A fecha de enero de 2026, ningún modelo de HuggingFace parece estar utilizando la biblioteca ml-flextok, salvo los modelos publicados por EPFL VILAB, que cuentan con decenas de miles de descargas en total.
Apple y EPFL VILAB han actualizado su código para resolver estos problemas utilizando YAML para analizar sus configuraciones y agregar una lista de clases permitidas que pasarán a la función instantiate() de Hydra. También han actualizado su documentación para indicar que las cadenas almacenadas en los archivos de modelo se ejecutan como código y que solo deben cargarse modelos de fuentes confiables.
Conclusión
Palo Alto Networks no ha identificado ningún archivo modelo que aproveche estas vulnerabilidades para realizar ataques en el mundo real. Sin embargo, los atacantes tienen muchas oportunidades para aprovecharlas.
Es habitual que los desarrolladores creen sus propias variaciones de modelos de última generación con diferentes ajustes y cuantificaciones, a menudo a partir de investigadores no afiliados a ninguna institución de prestigio. Los atacantes solo tendrían que crear una modificación de un modelo popular existente, con un beneficio real o supuesto, y luego agregar metadatos maliciosos.
Antes de este hallazgo, no había indicios de que estas bibliotecas pudieran ser inseguras o de que solo debieran cargarse archivos de fuentes confiables. HuggingFace no permite actualmente a los usuarios acceder fácilmente al contenido de los metadatos de estos archivos, como hace en otros casos (por ejemplo, las API a las que se hace referencia en los archivos .pickle). Tampoco señala los archivos que utilizan los formatos safetensors o NeMo como potencialmente inseguros.
Dado que los últimos avances en este ámbito suelen requerir código y no solo pesos de modelos, se ha producido una proliferación de bibliotecas de apoyo. En octubre de 2025, identificamos más de un centenar de bibliotecas Python diferentes utilizadas por los modelos de HuggingFace, de las cuales casi 50 utilizan Hydra de alguna manera. Aunque estos formatos por sí solos pueden ser seguros, existe una superficie de ataque muy grande en el código que los consume.
Protección y mitigación de Palo Alto Networks
Los clientes de Palo Alto Networks están mejor protegidos frente a las amenazas mencionadas gracias a los siguientes productos:
- Prisma AIRS es capaz de identificar modelos que aprovechan estas vulnerabilidades y extraer sus cargas útiles.
- La gestión de vulnerabilidades de Cortex Cloud identifica y gestiona imágenes base para máquinas virtuales en la nube y entornos contenedorizados. Esto permite identificar y alertar sobre vulnerabilidades y errores de configuración, y luego proporciona tareas de corrección para las imágenes de contenedores de nivel base identificadas. El agente Cortex Cloud también puede detectar las operaciones en tiempo de ejecución que se describen en este artículo.
- La evaluación de seguridad de IA de Unit 42 puede ayudar a las organizaciones a reducir el riesgo de adopción de la IA, proteger la innovación en IA y reforzar la gobernanza de la IA.
Si cree que puede haber resultado vulnerado o tiene un problema urgente, póngase en contacto con el equipo de respuesta ante incidentes de Unit 42 o llame al:
- Norteamérica: llamada gratuita: +1 (866) 486-4842 (866.4.UNIT42)
- Reino Unido: +44.20.3743.3660
- Europa y Oriente Medio: +31.20.299.3130
- Asia: +65.6983.8730
- Japón: +81.50.1790.0200
- Australia: +61.2.4062.7950
- India: 00 800 050 45107
- Corea del Sur: +82.080.467.8774
Palo Alto Networks ha compartido estos resultados con nuestros compañeros de Cyber Threat Alliance (CTA). Los miembros de CTA utilizan esta inteligencia para implementar rápidamente medidas de protección para sus clientes y desarticular sistemáticamente a los ciberdelincuentes. Obtenga más información sobre Cyber Threat Alliance.
Recursos adicionales
ÍNDICE
Relacionados Vulnerabilidades Recursos









