
Avant-propos
Nous avons identifié des vulnérabilités dans trois bibliothèques Python d’intelligence artificielle/de machine learning (IA/ML) open-source publiées par Apple, Salesforce et NVIDIA dans leurs référentiels GitHub. Lorsqu’un fichier modèle contenant des métadonnées malveillantes est chargé, les versions vulnérables de ces bibliothèques permettent l’exécution de code à distance (RCE).
Il s’agit notamment des bibliothèques suivantes :
- NeMo : un framework basé sur PyTorch créé à des fins de recherche et conçu pour le développement de divers modèles IA/ML et de systèmes complexes élaborés par NVIDIA.
- Uni2TS : une bibliothèque PyTorch créée à des fins de recherche et utilisée par Morai de Salesforce, un modèle de base pour l’analyse des séries temporelles qui prévoit les tendances à partir de vastes ensembles de données.
- FlexTok : un framework basé sur Python, créé à des fins de recherche, qui permet aux modèles IA/ML de traiter les images en exécutant les fonctions d’encodage et de décodage, développé par des chercheurs d’Apple et du laboratoire Visual Intelligence and Learning Lab de l’École polytechnique fédérale de Suisse.
Ces bibliothèques sont utilisées dans des modèles populaires sur HuggingFace avec des dizaines de millions de téléchargements au total.
Les vulnérabilités proviennent des bibliothèques qui utilisent des métadonnées pour configurer des modèles et des pipelines complexes, lorsqu’une bibliothèque tierce partagée instancie des classes à l’aide de ces métadonnées. Les versions vulnérables de ces bibliothèques exécutent simplement les données fournies sous forme de code. Un attaquant peut ainsi intégrer du code arbitraire dans les métadonnées du modèle, qui s’exécute automatiquement lorsque les bibliothèques vulnérables chargent ces modèles modifiés.
En décembre 2025, aucune attaque réelle utilisant ces vulnérabilités n’a été observée. Palo Alto Networks a notifié tous les fournisseurs concernés en avril 2025 afin qu’ils aient la possibilité de mettre en œuvre des mesures d’atténuation ou de résoudre les problèmes avant la publication.
- NVIDIA a publié des informations sur la vulnérabilité CVE-2025-23304, classée de gravité élevée, et a déployé un correctif dans la version 2.3.2 de NeMo.
- Les chercheurs ayant conçu FlexTok ont mis à jour leur code en juin 2025 pour résoudre ces problèmes.
- Salesforce a publié des informations sur la vulnérabilité CVE-2026-22584, classée de gravité élevée, et a déployé un correctif le 31 juillet 2025.
Ces vulnérabilités ont été détectées par Prisma AIRS, capable d’identifier les modèles exploitant ces vulnérabilités et d’extraire leurs payloads.
En complément, les clients de Palo Alto Networks bénéficient d’une protection renforcée contre les menaces décrites ci-dessus grâce aux produits et services suivants :
- Gestion des vulnérabilités de Cortex Cloud
- Le bilan de sécurité de l’IA d’Unit 42 aide les organisations à réduire les risques liés à l’adoption de l’IA, à sécuriser l’innovation en IA et à renforcer la gouvernance de l’IA.
- Si vous pensez que votre entreprise a pu être compromise ou si vous faites face à une urgence, contactez l’équipe Unit 42 de réponse à incident.
| Unit 42 - Thématiques connexes | Python, LLMs, Machine Learning |
Formats des modèles IA/ML
Les pipelines d’entraînement et d’inférence en IA/ML reposent sur la sauvegarde d’états internes complexes, tels que les poids appris et les définitions d’architecture. Ces états internes sont sauvegardés sous forme d’artefacts de modèle, qui, à leur tour, doivent être partagés entre les producteurs et les consommateurs. Les bibliothèques fournissent des mécanismes intégrés pour sérialiser ces artefacts.
Depuis longtemps, les bibliothèques Python dédiées à l’IA/ML reposent sur le module standard pickle pour enregistrer des objets Python dans des fichiers et les charger à partir de ces derniers. . Ce module sérialise les objets Python en créant un programme simple capable de les reconstruire. Il est exécuté lorsque les objets Python sont chargés. Comme ce module exécute du code au moment du chargement des fichiers, son utilisation entraîne des risques de sécurité importants.
Le format de fichier de la bibliothèque PyTorch intègre simplement les fichiers .pickle dans un format de conteneur. D’autres bibliothèques comme scikit-learn utilisent .pickle ou d’autres extensions associées à pickle (comme .joblib). La plupart des bibliothèques populaires d’IA/ML documentent clairement ces risques et proposent des mesures d’atténuation robustes pour empêcher l’exécution par défaut de code inattendu.
Failles de sécurité dans les nouveaux formats de modèles
De nouveaux formats ont été mis au point pour résoudre les problèmes de sécurité liés aux formats basés sur pickle. Ces formats dits « sûrs » y parviennent en grande partie en se limitant à la sérialisation des poids des modèles ou en décrivant les pipelines sous forme de données et non de code, à l’aide de formats tels que JSON. Par exemple, le format safetensors de HuggingFace ne permet de stocker que les poids des modèles et un seul objet JSON pour conserver les métadonnées des modèles.
Les formats plus anciens ont eux aussi progressivement abandonné l’utilisation du module pickle. Par exemple, PyTorch ne charge que les poids des modèles par défaut. Lorsque le chargement pickle est activé, PyTorch n’exécute que les fonctions d’une liste des autorisations prédéfinie qui devrait empêcher l’exécution de code arbitraire.
Même si ces nouveaux formats et mises à jour suppriment la possibilité de sérialiser les pipelines sous forme de code, ils ne rendent pas pour autant les applications et les bibliothèques utilisant ces modèles immunisées contre les exploits classiques. Des chercheurs en sécurité de JFrog ont identifié des vulnérabilités dans des applications utilisant ces formats, en exploitant des techniques bien connues telles que le cross-site scripting (XSS) et l’exploitation par chemin d’accès.
Analyse technique
Même si les formats récents ne permettent plus de stocker l’état des modèles et leurs configurations sous forme de code, les chercheurs ont toujours besoin de sérialiser ces informations dans certains cas. Étant donné la taille de ces bibliothèques et la complexité des configurations de leurs classes, de nombreuses bibliothèques recourent à des outils tiers pour gérer cette sérialisation.
Hydra, une bibliothèque Python optimisée par Meta, est couramment utilisée pour sérialiser l’état des modèles et les informations de configuration.
Nous avons identifié trois bibliothèques Python IA/ML open-source, utilisées par des modèles sur HuggingFace, qui exploitent Hydra pour charger ces configurations à partir des métadonnées des modèles d’une manière qui permet l’exécution de code arbitraire :
- NeMo : un framework basé sur PyTorch créé à des fins de recherche pour le développement de divers modèles IA/ML et de systèmes complexes développés par NVIDIA.
- Uni2TS : une bibliothèque PyTorch créée à des fins de recherche et utilisée par Morai de Salesforce, un modèle de base pour l’analyse des séries temporelles qui prévoit les tendances à partir de vastes ensembles de données.
- FlexTok : un framework basé sur Python, créé à des fins de recherche, qui permet aux modèles IA/ML de traiter les images en exécutant les fonctions d’encodage et de décodage, développé par des chercheurs d’Apple et du laboratoire Visual Intelligence and Learning Lab de l’École polytechnique fédérale de Suisse.
Hydra
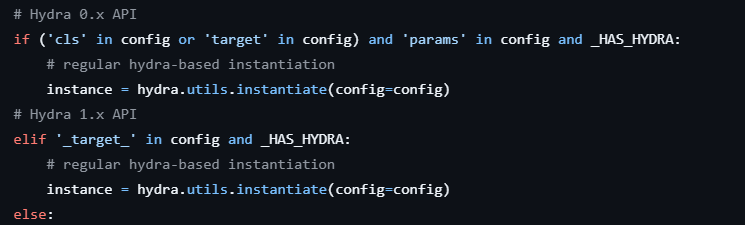
Toutes les vulnérabilités que nous avons identifiées utilisent la fonction hydra.utils.instantiate(), dont l’objectif est « d’instancier différentes mises en œuvre d’une interface ».
L’API Hydra prend comme argument un objet de configuration (comme un dictionnaire Python ou un objet OmegaConf) qui décrit l’interface cible à instancier ainsi que des paramètres optionnels *args et **kwargs à transmettre à cette interface. Cette configuration attend une valeur _target_ spécifiant la classe ou la fonction appelable à instancier, ainsi qu’une valeur optionnelle _args_ définissant les arguments à transmettre à _target_.
Dans chacun des cas identifiés, hydra.utils.instantiate() n’est utilisé que pour instancier des instances de classes de bibliothèques avec des arguments simples stockés dans les métadonnées. La figure 1 montre un exemple de métadonnées que NeMo transmet à la fonction instantiate().
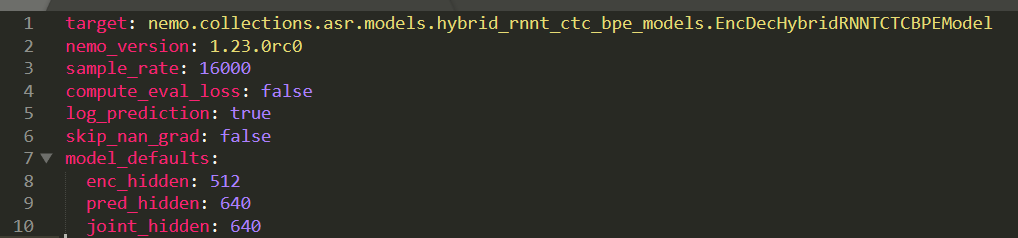
Ce que ces bibliothèques semblent avoir négligé, c’est que instantiate() n’accepte pas seulement le nom des classes à instancier, mais aussi le nom de toute fonction appelable et lui transmet les arguments fournis.
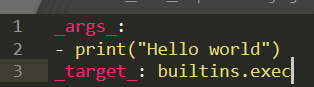
En exploitant cela, un attaquant peut plus facilement réaliser une exécution de code à distance (RCE) en utilisant les fonctions intégrées de Python telles que eval() et os.system(). Dans toutes les preuves de concept que nous avons utilisées pour tester ces vulnérabilités, nous avons employé un payload utilisant builtins.exec() comme fonction appelable et une chaîne contenant du code Python comme argument.
Depuis la découverte de ces vulnérabilités, Hydra a été mis à jour pour ajouter un avertissement à sa documentation précisant qu’une exécution de code à distance (RCE) avec instantiate(), et pour intégrer un mécanisme simple de liste de blocage. Ce mécanisme consiste à comparer la valeur _target_ à une liste de fonctions dangereuses telles que builtins.exec() avant qu’elle ne soit appelée.
Parce que ce mécanisme utilise des correspondances exactes avec les cibles d’importation avant leur chargement, il peut être contourné très facilement en utilisant des importations implicites de la bibliothèque standard de Python (p. ex., enum.bltns.eval) ou de l’application cible (p. ex., nemo.core.classes.common.os.system). Cependant, la documentation de Hydra indique clairement que ce mécanisme n’est pas exhaustif et qu’il ne doit pas être utilisé comme seule mesure pour empêcher l’exécution de code malveillant. En janvier 2026, ce mécanisme de liste de blocage n’est toujours pas disponible dans une version publiée de Hydra.
NeMo
Depuis 2019, NVIDIA développe la bibliothèque NeMo en tant que « framework d’IA générative évolutive et cloud-native ». NeMo utilise ses propres formats de fichiers avec les extensions .nemo et .qnemo, qui sont en réalité des fichiers TAR contenant un fichier model_config.yaml qui stocke les métadonnées du modèle, ainsi qu’un fichier .pt ou .safetensors, selon le cas.
Les principaux points d’entrée pour charger ces fichiers de modèles .nemo sont restore_from() et from_pretrained(). Derrière plusieurs couches d’abstraction, c’est finalement un module mixte de sérialisation qui est utilisé pour gérer le chargement de la configuration du modèle une fois celle-ci extraite du fichier model_config.yaml intégré. La figure 2 met en évidence l’appel vulnérable de hydra.utils.instantiate().
À aucun moment, les métadonnées ne sont nettoyées avant d’être transmises à instantiate(). Étant donné que l’appel est effectué avant que la classe de modèle cible ne commence son initialisation, il est facile de créer un fichier model_config.yaml contenant un payload opérationnel, comme indiqué à la figure 3.
NeMo s’intègre également à HuggingFace et permet de transmettre le nom d’un modèle hébergé sur HuggingFace à from_pretrained(), ce qui correspond à la façon dont la plupart des modèles NeMo sur HuggingFace sont utilisés. Cet appel reste vulnérable parce qu’une fois le modèle téléchargé depuis HuggingFace, les mêmes chemins de code sont exécutés.
En janvier 2026, plus de 700 modèles sur HuggingFace provenant de divers développeurs sont fournis au format NeMo. Un grand nombre de ces modèles figurent parmi les plus populaires sur HuggingFace, comme parakeet de NVIDIA. Cette vulnérabilité semble exister depuis au moins 2020.
Le format PyTorch sur lequel s’appuie NeMo autorise l’exécution de code via des fichiers .pickle intégrés, mais cela est clairement documenté. Ce format PyTorch désactive également l’exécution arbitraire par défaut et offre plusieurs mécanismes de protection, tels que la mise en liste blanche des modules utilisables lors du chargement des fichiers .pickle. NeMo permet de charger des fichiers .pickle intégrés dans les fichiers PyTorch contenus dans les fichiers .nemo, mais le mécanisme de liste des autorisations intégré à PyTorch devrait empêcher toute exécution de code arbitraire.
NVIDIA a reconnu ce problème, a publié des informations sur la vulnérabilité CVE-2025-23304, classée de gravité élevée, et a déployé un correctif dans la version 2.3.2 de NeMo.
Pour résoudre ce problème, NeMo a ajouté une fonction safe_instantiate pour valider les valeurs _target_ des configurations Hydra avant leur exécution. Cette fonction recherche de manière récursive les valeurs _target_ dans la configuration et valide chacune d’entre elles, empêchant ainsi l’utilisation d'objets imbriqués pour l’exécution de code à distance (RCE). Une nouvelle fonction _is_target_allowed vérifie d’abord chaque valeur _target_ en la comparant à une liste des préfixes autorisés contenant des noms de packages de NeMo, PyTorch et de bibliothèques associées.
Cette vérification des préfixes ne suffirait pas à empêcher l’importation implicite de modules dangereux, comme c’est le cas pour le nouveau mécanisme de liste de blocage de Hydra. Cependant, NeMo va plus loin et importe chaque cible via Hydra et vérifie ensuite si :
- Il s’agit d’une sous-classe d’une classe attendue.
- le nom du module importé figure dans une liste des autorisations de modules attendus.
En vérifiant la valeur réellement importée par rapport à ces listes d’autorisations, NeMo s’assure que seules les cibles attendues sont exécutées. Par exemple, la cible nemo.core.classes.common.os.system renvoie au module posix, qui ne fait manifestement pas partie de la bibliothèque NeMo.
Uni2TS
En 2024, l’équipe de recherche en IA de Salesforce a publié un article intitulé Unified Training of Universal Time Series Transformers (Formation unifiée des transformateurs de séries temporelles universelles), présentant un ensemble de modèles publiés sur le site HuggingFace. Cet article et l’utilisation de ces modèles dépendent de uni2TS, une bibliothèque Python open-source publiée en même temps que l’article de Salesforce.
La bibliothèque uni2TS fonctionne exclusivement avec des fichiers .safetensors, qui ont été explicitement conçus pour offrir une alternative sûre aux formats de modèles permettant l’exécution de code. Le format safetensors ne permet pas non plus de stocker explicitement les configurations de modèles ou de pipelines.
Pour faciliter le stockage de ces configurations, des bibliothèques telles que huggingface_hub de HuggingFace utilisent un fichier config.json stocké dans le référentiel d’un modèle. Pour les modèles utilisant des classes d’une des bibliothèques ML centrales de HuggingFace, cette opération se fait en toute sécurité, car seuls les paramètres pouvant être stockés directement sous forme de types primitifs JSON sont utilisés. Ces valeurs sont ensuite transmises à un ensemble de classes prédéfinies et codées en dur.
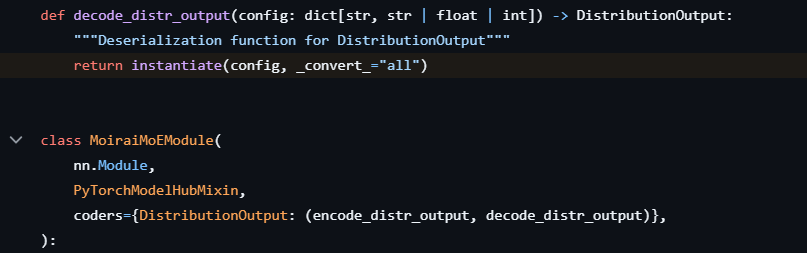
Cependant, huggingface_hub fournit une interface PyTorchModelHubMixin pour créer des classes de modèles personnalisées qui peuvent être intégrées au reste de leur framework. Dans le cadre de cette interface, les valeurs sont lues à partir du fichier config.json et transmises à la classe du modèle.
Cette interface fournit un mécanisme peu utilisé pour enregistrer des fonctions appelées codeurs, qui traitent certains arguments avant qu’ils ne soient transmis à la classe. La bibliothèque uni2TS exploite ce mécanisme pour décoder la configuration d’un argument spécifique à l’aide d’un appel à hydra.utils.instantiate() avant qu’il ne soit transmis à la classe cible, comme indiqué à la figure 4.
Ce code est exécuté lorsque l’un des modèles publiés est chargé via MoraiModule.from_pretrained() ou MoraiMoEModule.from_pretrained(). En ajoutant notre payload au fichier config.json fourni avec les modèles utilisant uni2TS, comme indiqué à la figure 5, il est possible de réaliser une exécution de code à distance (RCE) lors du chargement du modèle.
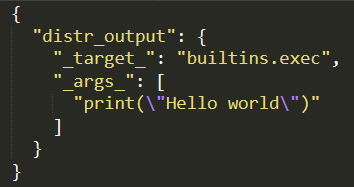
Les modèles Salesforce comptent déjà des centaines de milliers de téléchargements sur HuggingFace. Plusieurs adaptations de ces modèles ont également été publiées sur HuggingFace par d’autres utilisateurs. Aucune preuve d’activité malveillante impliquant ces modèles n’a été détectée.
Salesforce a reconnu ce problème, a publié des informations sur la vulnérabilité CVE-2026-22584, classée de gravité élevée, et a déployé un correctif le 31 juillet. Ce correctif met en œuvre une liste des autorisations et un contrôle de validation strict afin de garantir que seuls les modules explicitement autorisés peuvent être exécutés.
ml-flextok
Début 2025, Apple et le laboratoire Visual Intelligence and Learning Lab de l’École polytechnique fédérale de Suisse (EPFL VILAB) ont publié des recherches présentant une bibliothèque Python associée appelée ml-flextok. Comme uni2TS, ml-flextok fonctionne exclusivement avec le format safetensors et étend PyTorchModelHubMixin. Il peut également charger des métadonnées à partir d’un fichier config.json inclus dans le référentiel de modèles. Cette bibliothèque permet également de charger directement les données de configuration du fichier .safetensors, en stockant ces informations dans la section des métadonnées du fichier sous la clé __metadata__.
Comme le format safetensors représente les métadonnées sous forme de dictionnaire dont les clés et les valeurs sont des chaînes de caractères, et comme la configuration du modèle dépend de listes de paramètres, un codage secondaire doit être utilisé. ml-flextok utilise Python comme codage secondaire et recourt à ast.literal_eval() de la bibliothèque standard de Python pour décoder les métadonnées.
Comme indiqué dans la documentation, cette fonction ne permet pas l’exécution de code arbitraire, mais elle est susceptible de faire l’objet d’attaques entraînant l’épuisement de la mémoire, une consommation excessive du processeur et le blocage du processus. Une fois les métadonnées décodées, ml-flextok les transmet directement à la fonction hydra.utils.instantiate().
Si le modèle est chargé à partir de HuggingFace, ces métadonnées sont lues depuis config.json et ne sont pas doublement codées, car les structures complexes sont prises en charge. Ces données JSON sont chargées sous forme de dictionnaire, et des sections spécifiques sont transmises directement à la fonction instantiate().
Dans les deux cas, les payloads sont créés avec des noms correspondant aux arguments de instantiate(). Que le payload soit ajouté directement au fichier .safetensors ou au package config.json, son codage et son emplacement diffèrent légèrement, mais l’exploitation reste simple et directe. La figure 6 illustre le payload placé dans les métadonnées d’un fichier .safetensors.

En janvier 2026, aucun modèle sur HuggingFace ne semble utiliser la bibliothèque ml-flextok, à l’exception de ceux publiés par EPFL VILAB, qui cumulent des dizaines de milliers de téléchargements au total.
Apple et EPFL VILAB ont mis à jour leur code pour corriger ces vulnérabilités en utilisant des fichiers YAML pour analyser leurs configurations et en ajoutant une liste de classes autorisées transmise à la fonction instantiate() de Hydra. Ils ont également mis à jour leur documentation pour indiquer que les chaînes de caractères stockées dans les fichiers de modèles sont exécutées comme du code et que seuls les modèles provenant de sources fiables doivent être chargés.
Conclusion
Palo Alto Networks n’a identifié aucun fichier de modèle exploitant ces vulnérabilités dans des attaques réelles. Cependant, les attaquants ont de nombreuses possibilités de le faire.
Il est courant que les développeurs créent leurs propres variantes des modèles de pointe avec différents réglages et quantifications, souvent provenant de chercheurs non affiliés à des institutions reconnues. Un attaquant n’aurait qu’à modifier un modèle populaire existant, en promettant un avantage réel ou supposé, puis à ajouter des métadonnées malveillantes.
Avant cette découverte, rien n’indiquait que ces bibliothèques pouvaient être vulnérables ou qu’il fallait charger uniquement des fichiers provenant de sources fiables. De plus, HuggingFace ne rend pas le contenu des métadonnées de ces fichiers facilement accessible aux utilisateurs comme il le fait dans d’autres cas (par exemple, les API référencées dans les fichiers .pickle). Il ne signale pas non plus les fichiers au format safetensors ou NeMo comme étant potentiellement dangereux.
Enfin, comme les dernières avancées dans ce domaine requièrent souvent du code et pas seulement des poids de modèles, on observe une prolifération de bibliothèques associées. En octobre 2025, nous avons identifié plus d’une centaine de bibliothèques Python différentes utilisées par des modèles sur HuggingFace, dont près de 50 exploitent Hydra d’une manière ou d’une autre. Même si ces formats sont sûrs en eux-mêmes, le code qui les exploite présente une vaste surface d’attaque.
Protection et atténuation des risques par Palo Alto Networks
Les clients de Palo Alto Networks sont mieux protégés contre les menaces décrites ci-dessus grâce aux produits suivants :
- Prisma AIRS est capable d’identifier les modèles exploitant ces vulnérabilités et d’extraire leurs payloads.
- La gestion des vulnérabilités de Cortex Cloud identifie et gère les images de base pour les environnements cloud de machines virtuelles et de conteneurs. Cela permet de détecter et de signaler les vulnérabilités et les configurations erronées, puis de fournir des tâches de remédiation pour les images de conteneurs de niveau de base identifiées. L’agent Cortex Cloud permet également de détecter les opérations du runtime décrites dans cet article.
- Le bilan de sécurité de l’IA d’Unit 42 aide les organisations à réduire les risques liés à l’adoption de l’IA, à sécuriser l’innovation en IA et à renforcer la gouvernance de l’IA.
Si vous pensez que votre entreprise a pu être compromise ou si vous faites face à une urgence, contactez l’équipe Unit 42 de réponse à incident ou composez l’un des numéros suivants :
- Amérique du Nord : Gratuit : +1 (866) 486-4842 (866.4.UNIT42)
- Royaume-Uni : +44 20 3743 3660
- Europe et Moyen-Orient : +31.20.299.3130
- Asie : +65.6983.8730
- Japon : +81 50 1790 0200
- Australie : +61.2.4062.7950
- Inde : 000 800 050 45107
- Corée du Sud : +82.080.467.8774
Palo Alto Networks a partagé ces conclusions avec les autres membres de la Cyber Threat Alliance (CTA). Les membres de la CTA s’appuient sur ces renseignements pour déployer rapidement des mesures de protection auprès de leurs clients et perturber de manière coordonnée les activités des cybercriminels. Cliquez ici pour en savoir plus sur la Cyber Threat Alliance.
Pour aller plus loin
- Documentation de Hydra – Hydra
- Code source de NeMo – NVIDIA-NeMo on GitHub
- Code source de uni2ts – SalesforceAIResearch on GitHub
- Code source de ml-flextok – Apple on GitHub
- Modèles NeMo sur HuggingFace – HuggingFace
SOMMAIRE
Associé Vulnérabilités Ressources









