
Executive Summary
AI agents now extend their capabilities by installing third-party skills the way smartphones install apps. Anyone can publish a skill to a public registry. Anyone can install one into a production agent. And until now, no automated tool has verified what a skill does before it gains privileged access to credentials, files and shell commands inside that agent.
We introduce Behavioral Integrity Verification (BIV), an audit primitive that compares what a skill claims to do against what it does, across all three of its surfaces:
- Metadata
- Executable code
- Natural-language instructions
Applied at registry scale, BIV finds that most skills deviate from declared behavior. The vast majority of those gaps are sloppy documentation, not malice. But a smaller, dangerous slice carries multi-stage attack chains, where individually benign-looking capabilities combine into credential theft, remote code execution or silent data exfiltration.
The agent-skill ecosystem now stands where mobile applications and browser extensions were a decade ago. Extensibility has outpaced the supply-chain audit primitives that should gate it. Security teams running large language model (LLM) agents in production should inventory the third-party skills installed and require a behavioral-integrity check before installation rather than after.
Palo Alto Networks customers are better protected from this type of issue through the following products and services:
The Unit 42 AI Security Assessment can help empower safe AI use and development.
If you think you might have been compromised or have an urgent matter, contact the Unit 42 Incident Response team.
| Related Unit 42 Topics | LLM, AI Agents, Supply Chain |
Background
Enterprises now deploy LLM agents to automate tasks across code generation, IT operations, customer support and internal workflows. These agents are extended with skills, the agent equivalent of an app: a small package that bundles executable code with a YAML manifest and a natural-language SKILL.md file telling the agent when and how to use it.
Once installed, a skill runs inside the agent's privileged context. It can read environment variables, call external services, write files and execute shell commands on behalf of the organization.
Public agent-skill registries now host tens of thousands of these packages. Anyone can publish. Anyone can install.
The platforms that came before, package managers, mobile app stores and browser extension marketplaces, all eventually grew automated audit ecosystems after attackers turned the openness against users. The agent-skill ecosystem has not.
The audit problem in this ecosystem differs from anything earlier platforms faced. A skill's behavior splits across three modalities:
- Metadata
- Executable code
- Natural-language instructions
The metadata declares what the skill is supposed to do. The code and instructions together drive what it does. No existing scanner reads all three, and the registry has no automated way to verify that the two sides match. BIV is the audit primitive that compares them.
The Method: Declared Vs. Actual Behavior
BIV asks one question of every skill: Does what it says match what it does?
To answer that question consistently across tens of thousands of skills, BIV needed a shared vocabulary. We used a fixed taxonomy of 29 capabilities organized into seven families:
- Network
- File system
- Process execution
- Environment
- Encoding
- Credentials
- Instruction-level threats
Two parallel tracks populate the taxonomy:
- The declared track reads the metadata. Deterministic parsers handle structural fields like YAML frontmatter and schemas. An LLM then reads natural-language descriptions (README, SKILL.md prose) to extract claimed capabilities, ensuring each claim is grounded in a quoted source span.
- The actual track reads the code and instructions. Static analyzers cover code across multiple scripting languages (Python, JavaScript, shell) using abstract syntax tree (AST)-level taint analysis, regex and pattern matching. Separately, an LLM reads the natural-language instructions to surface prompt-injection and instruction-override motifs that traditional parsers miss.
A skill passes when its actual capability set fits inside its declared capability set. A skill fails when it does something it never disclosed (an under-specification, the operationally dangerous direction) or declares a permission it never exercises (an over-specification, almost always benign template residue).
Three filters keep the LLM components honest:
- The first rejects any output that echoes the taxonomy verbatim.
- The second rejects capability claims not anchored in a quoted source span.
- The third requires domain-specific keywords in context for high-risk capabilities.
The pipeline ships with file-and-line evidence pointers, so every flagged deviation is auditable by hand.
Findings in the Wild
We crawled the OpenClaw agent-skill registry in early 2026 and ran BIV across all 49,943 listed skills. BIV surfaced 250,706 behavioral deviations, with 80.0% of skills (39,933) showing at least one mismatch between declaration and behavior.
A clustering pass over the deviation explanations produced a 137-cluster taxonomy and, notably, four novel compound threat categories. Each is a multi-step pattern:
- Exfiltration chains (FILE_READ → base64 → NETWORK_SEND)
- Remote code execution (RCE) chains (download → write → execute)
- Code obfuscation (encoding chain → dynamic eval)
- Data lineage violations (FILE_READ → FILE_WRITE, mostly benign data-pipeline boilerplate)
The threat lives in the chain, not the link. A scanner that checks one capability at a time sees a file read in one row and a network send in another and flags neither in isolation. BIV's contribution is the link between them.
A capability mismatch tells us that something undeclared is happening, not whether the developer was sloppy or hostile. BIV separates the two with a two-step intent classifier.
A deterministic rule engine resolves roughly two-thirds of cases at near-zero cost. An LLM classifier handles the rest by reasoning across a skill's full deviation list, so a multi-step chain is judged as a unit. Figure 1 breaks down 163,754 classified deviations by root cause.

Our analysis of this breakdown reveals that the skill ecosystem's primary failure mode is specification immaturity, not pervasive malice. Specifically, the classified data highlights two key themes:
- 81.1% were traced to developer oversight. Documentation errors lead, followed by legitimate helper code, unused declarations and framework dependencies. These call for documentation outreach at the registry, not security review.
- 18.9% were traced to adversarial intent. This adversarial slice concentrates sharply in data theft and espionage (60% of the adversarial total), then payload and infrastructure, and agent hijacking. Financial, destructive and social engineering combined come to under 1%.
When analyzed at the skill level, the registry decomposes into three governance tiers. The top tier is 5.0% of the registry (2,490 skills) that carry multi-stage attack chains and warrant mandatory security review. The middle tier is 16.8% that carry single-stage adversarial deviations and warrant contextual review. The remaining 72.5% are benign skills whose declared metadata simply needs to catch up to the code.
The top tier has structure worth leveraging. The 2,490 skills carrying multi-stage chains are not 2,490 unrelated alerts.
Two patterns dominate:
- Silent credential exfiltration (read a secret, transmit it)
- Instruction-override hijacking (take over the agent's decision loop, then exfiltrate)
Together, they cover 88% of all multi-stage chains. For an analyst running incident response or a registry operator setting review policy, this is operationally significant. The first 88% of the review effort can target two well-defined patterns instead of a flat list.
Where the Real Risk Concentrates
The adversarial fraction of deviations varies sharply across the seven capability families. A registry-wide threshold either over-blocks routine I/O skills or under-reviews the genuinely dangerous categories. Figure 2 plots each category by its adversarial fraction and deviation volume, with compound threat categories indicated by red stars.
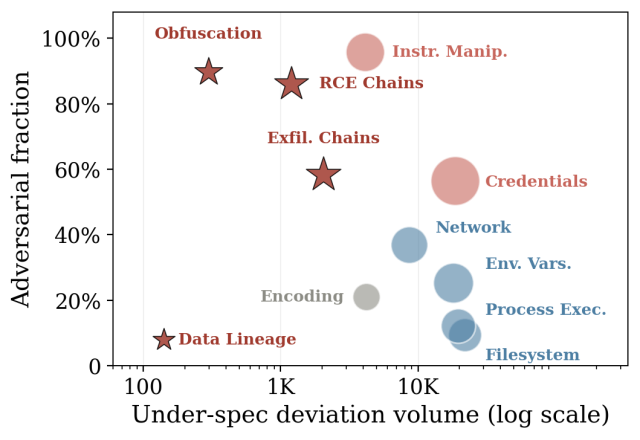
As the plot illustrates, three of the four compound threat categories sit in the high-adversarial region. Data lineage violations, dominated by benign data-pipeline boilerplate, is the outlier. We noted the following trends in other threat categories:
- Instruction manipulation: 96% adversarial. The smallest established capability surface but the highest signal-to-noise ratio. Almost every undeclared prompt-control directive is suspect. This is the agent-specific attack surface that no prior third-party platform had to defend.
- Credentials: 56% adversarial. It reflects the operational value of secrets to attackers.
- Network: 37% adversarial. Mid-band; legitimate uses compete with exfiltration motifs.
- File system (10%) and process execution (12%): Predominantly benign. Routine I/O and command invocation dominate raw volume but rarely indicate hostile intent on their own.
Operationally, this argues for per-category review tiers keyed to BIV's per-capability severity (Critical for credentials and instruction-level capabilities; high for network, process and environment access; medium for file system and encoding). A single threshold is the wrong instrument for this surface.
Beyond the per-capability picture, multi-stage compound chains define the highest-priority hunt patterns. The two dominant exfiltration patterns described above cover 88% of multi-stage chains; four long-tail patterns cover dropper-style payload delivery, encoding-based evasion, persistence and reconnaissance-then-exfiltration. Any installed skill matching one of these six patterns warrants mandatory review.
Conclusion
The agent-skill ecosystem mirrors an inflection point seen in mobile applications and browser extensions a decade ago, where extensibility similarly outpaced audit capabilities. Each of those earlier ecosystems stabilized only after automated cross-modality auditing became routine.
The proposed BIV method reduces the multi-modality audit problem to a typed comparison over a shared capability vocabulary. The same structured evidence supports a registry-scale deviation taxonomy and a two-step root-cause classifier.
The registry-scale findings reveal a clear operational strategy. Documentation interventions at the registry can address the 81.1% non-adversarial bulk. Security review efforts can then focus on the 18.9% that matters, specifically targeting the two dominant attack patterns.
The following limitations should be acknowledged.
- BIV is static-only, dynamic dispatch and obfuscated payloads escape AST-level analysis.
- Flagged skills are classifier-predicted candidates for review, not runtime-confirmed exploits.
- The pipeline is not robust against an adversary who has read this paper and crafts descriptions calibrated to confuse the LLM adjudicator.
- Backbone backdoors, retrieval-corpus poisoning and runtime memory poisoning fall outside scope and require complementary runtime defenses.
For organizations deploying LLM agents in production today, the action is concrete. Inventory the third-party skills installed and implement a behavioral-integrity check before installation rather than after.
We detailed the full methodology and complete registry-scale analysis behind this post in our research paper.
Palo Alto Networks Protection and Mitigation
Palo Alto Networks customers are better protected from the threats discussed above through the following products:
- Prisma AIRS is designed to provide layered, real-time protection for AI systems by detecting and blocking threats, preventing data leakage and enforcing secure usage policies across a variety of AI applications.
The Unit 42 AI Security Assessment can help empower safe AI use and development.
If you think you may have been compromised or have an urgent matter, get in touch with the Unit 42 Incident Response team or call:
- North America: Toll Free: +1 (866) 486-4842 (866.4.UNIT42)
- UK: +44.20.3743.3660
- Europe and Middle East: +31.20.299.3130
- Asia: +65.6983.8730
- Japan: +81.50.1790.0200
- Australia: +61.2.4062.7950
- India: 000 800 050 45107
- South Korea: +82.080.467.8774
Palo Alto Networks has shared these findings with our fellow Cyber Threat Alliance (CTA) members. CTA members use this intelligence to rapidly deploy protections to their customers and to systematically disrupt malicious cyber actors. Learn more about the Cyber Threat Alliance.
Additional Resources
Table of Contents
Related Malware Resources

 High Profile Threats
High Profile Threats






 Threat Actor Groups
Threat Actor Groups
